2023-5-8 AI Insights: Novel image editing technique, Conditioning pretrained unconditional generative models, and more!
Controllable Image Generation via Collage Representations
Generative AI has made tremendous strides in recent years, with applications ranging from art and design to data augmentation and virtual reality. However, one significant challenge remains: achieving fine-grained controllability in image generation. Text-based diffusion models and layout-based conditional models have made some progress in this area, but they often fall short in providing detailed appearance characteristics. Through an elegant solution, the Mix and Match (M&M) model leverages collage representations to achieve superior scene controllability without compromising image quality.

Problem Statement
Fine-grained generative controllability is essential for tasks like image editing, style transfer, and content generation. Traditional methods, such as text-based diffusion models, require intricate prompt engineering, while layout-based conditional models depend on coarse semantic labels that cannot capture detailed appearance characteristics. Moreover, existing models that attempt to create interpretable and linearly-separable latent spaces for object appearance control face challenges in identifying which latent dimensions correspond to specific features, necessitating semi-supervised training approaches.
Proposed Solution: Mix and Match (M&M) Model
At a high level, this work proposes the Mix and Match (M&M) model, which works by taking an image collage as input, extracting representations of the background image and foreground objects, then spatially arranging these representations to generate high quality, non-deterministic images that are highly similar to the input collage.
Key Components of the M&M Model
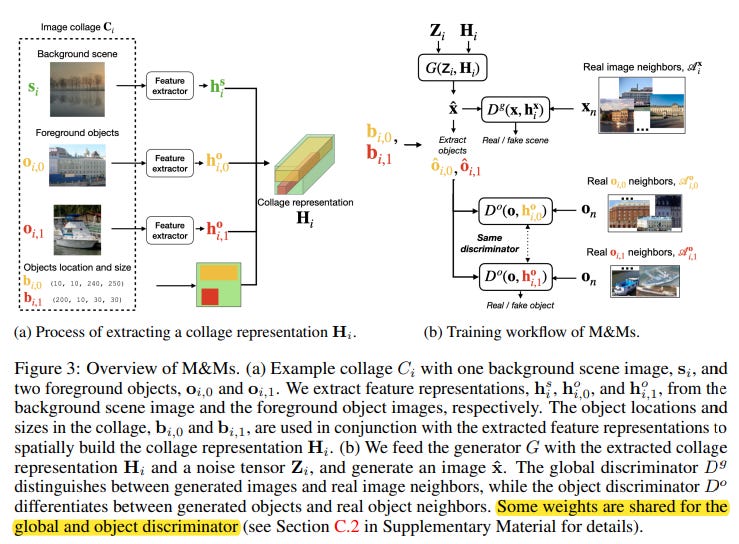
The M&M model consists of several key components, including a pre-trained feature extractor, a generator, and two discriminators operating at the image and object levels. By leveraging neighboring instances in feature space, the M&M model can model local densities and blend multiple localized distributions (one per collage element) into coherent images.
Generator: The generator takes in a noise tensor Z_i and a representation tensor H_i. Z_i is composed of scene noise and object noise vectors spatially arranged using collage bounding boxes, while H_i encodes the image collage's background scene and each collage element into feature space, arranged using bounding boxes.
Training: The M&M model employs global and object discriminators to discern between k-NN for image x and images generated conditioned on H_i. These discriminators share some weights and use cosine similarity to compute neighbors.
Explicit Key Contributions:
- The M&M model introduces collage-based conditioning as a simple yet effective way to control scene generation.
- M&M generates coherent images from collages that combine random objects and scenes, offering superior scene controllability without affecting image quality.

Comparison with SOTA
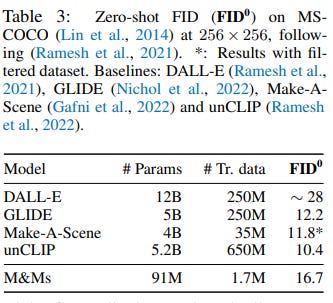
The M&M method was tested for zero-shot transfer on MS-COCO validation images by conditioning it on collages derived from the dataset. When compared with recent text-to-image models in terms of zero-shot FID, M&M achieves competitive results, surpassing DALL-E despite using a smaller model with 131× fewer parameters and being trained on 147× fewer images. The method also demonstrates exceptional controllability, quality, and diversity when combining objects and scenes from different images using user-chosen bounding box coordinates to construct creative collages.
Future Works and Limitations
The current M&M model leverages features from a pre-trained feature extractor and depends on it. Jointly training M&M with the feature extractor could be explored in future work. Additionally, when object